Chuỗi bài viết “Machine Learning is Fun!” này mình lược dịch từ bài viết gốc của tác giả ageitgey. Mình tin chắc có rất nhiều bạn đã và đang quan tâm đến Machine Learning hiện nay. “Machine Learning is Fun!” chắc chắn sẽ mang cho bạn đến cho bạn cái nhìn từ cơ bản đến chuyên sâu nhất về thế giới Machine Learning.
Bài gốc: https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471
Bạn đã từng nghe rất nhiều người nói về Machine Learning, nhưng chúng chỉ là các thông tin rất mù mờ?
Chuỗi bài viết này dành cho những ai muốn tìm hiểu về Machine Learning nhưng chưa biết bắt đầu từ đâu. Tôi cá rằng có rất nhiều người đã cố gắng đọc bài viết về Machine Learning này trên Wikipedia, và họ phải rất vọng và bỏ cuộc vì những định nghĩa giải thích trong đó.
Machine Learning là gì?
Machine Learning là một ý tưởng về một thuật toán tổng quát chung có thể nói cho bạn biết vài điều về các khía cạnh khác nhau của bộ dữ liệu, mà bạn không cần phải viết bất cứ dòng code đặc biệt nào để giải quyết vấn đề. Thay vì bạn viết code, bạn đổ dữ liệu vào các thuật toán và chúng sẽ tự xây dựng các logic dựa vào dữ liệu đó.
Ví dụ, một loại thuật toán cơ bản đó là phân lớp (classification algorithm), thuật toán này cho phép chia dữ liệu thành nhiều nhóm khác nhau. Một thuật toán dùng để nhận dạng chữ số viết tay (recognize handwritten numbers) có thể được sử dụng để phân loại email (thành spam và không spam), mà không cần phải code lại.
Hai bài toán trên không một thuật toán, nhưng khác dữ liệu.
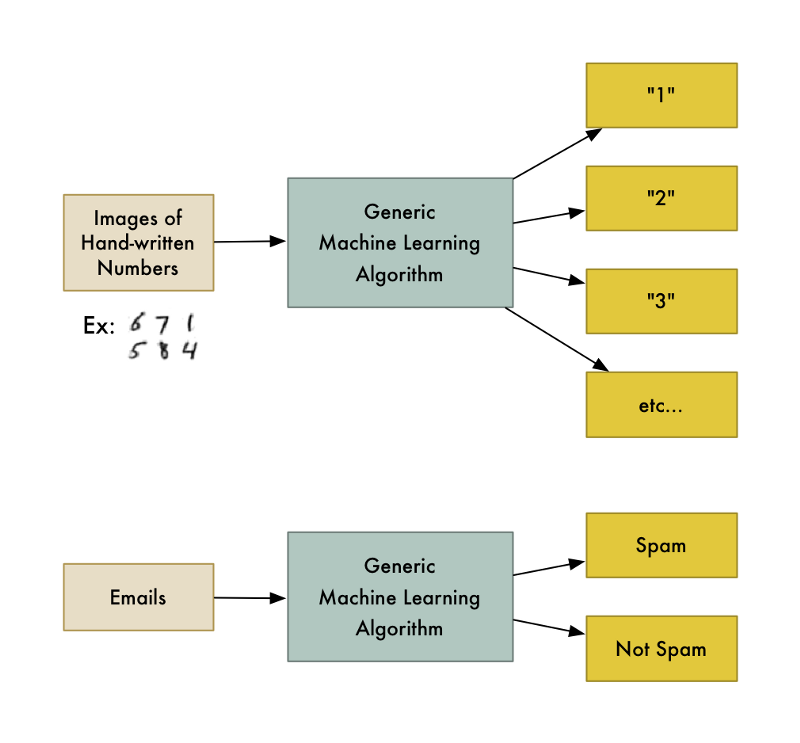 Thuật toán Machine Learning này là black-box, có thể được sử dụng để giải quyết nhiều bài toán phân lớp khác nhau.
Thuật toán Machine Learning này là black-box, có thể được sử dụng để giải quyết nhiều bài toán phân lớp khác nhau.
“Machine Learning” là một thuật ngữ chung bao hàm rất nhiều thuật toán như trên.
Hai loại thuật toán Machine Learning
Thuật toán của Machine Learning được chia thành hai nhóm lớn - học giám sát (supervised learning) và học không giám sát (unsupervised learning). Sự khác nhau giữa hai nhóm này đơn giản, nhưng rất quan trọng.
Supervised Learning
Giả sử bạn là một người làm về bất động sản. Công ty của bạn phát triển nhanh, bạn tuyển hàng loạt thực tập. Nhưng có một vấn đề - bạn có thể dễ dàng nhìn lướt qua và đánh giá chính xác giá trị của một ngôi nhà, nhưng với các thực tập viên không có kinh nghiệm, họ không biết mỗi căn trị giá bao nhiêu.
Để giúp đỡ các bạn thực tập này, bạn quyết định viết một ứng dụng nhỏ có thể ước lượng được giá của một ngôi nhà dựa vào _diện tích, khu vực lân cận, … _
Và bạn ghi lại thông tin của mọi căn nhà được bán trong thành phố, trong vòng 3 tháng. Với mỗi ngôi nhà, bạn ghi lại mọi thông tin: số phòng ngủ, diện tích (feet vuông), neighborhood, … Nhưng quan trọng nhất là giá (price) cuối cùng của căn nhà được bán:
 Chúng ta có được “training data”
Chúng ta có được “training data”
Với dữ liệu “training data” như trên, chúng ta muốn viết một ứng dụng có thể ước tính được giá của một căn nhà tương tự khác:

Chúng ta muốn sử dụng training data để dự đoán giá của những ngôi nhà khác.
Đây được gọi là supervised learning. Bạn biết được giá mỗi căn nhà được bán đi, nói cách khác, bạn biết được câu trả lời của bài toán, và có thể từ đây suy ra được logic của vấn đề.
Để xây dựng ứng dụng này, bạn cho training data về mỗi ngôi nhà này vào một thuật toán machine learning. Thuật toán sẽ cố gắng tìm ra loại tính toán nào để các con số có thể work.
Nó giống như việc tìm các toán tử trong bài tập toán hồi lớp 1 chúng ta vẫn hay được học:

Từ bảng trên, bạn có thể tìm ra được các phép toán nào để có được kết quả bên phải? Bạn biết bạn có nghĩa vụ phải “làm gì đó” với những con số ở bên trái để có được câu trả lời ở bên phải.
Với supervised learning, bạn đang để máy tính phải tìm ra những quan hệ đó cho bạn. Và một khi bạn biết những phép toán nào cần để giải một số bài toán trên, bạn có thể giải bất kỳ bài toán khác cùng loại!
Unsupervised Learning
Quay lại với ví dụ bất động sản, giả sử bạn không biết thông tin gì về giá. Chỉ với thông tin về diện tích, vị trí, … bạn vẫn có thể làm được vài thứ hay ho. Đây được gọi là unsupervised learning.

Mặc dù bạn không thể dự đoán được giá nhà, bạn vẫn có thể làm vài chuyện hay khác với Machine Learning
Bài toán này giống như ai đó đưa cho bạn một đống hồ sơ và bảo rằng “Tao không biết mấy con số này có nghĩa gì, nhưng mà tao nghĩ mày có lẽ sẽ tìm ra được một pattern nào đó, hoặc chia thành các nhóm, hoặc là một cái gì khác. OK?”
Vậy chúng ta có thể làm gì với data này? Với người mới bắt đầu, bạn có thể có một thuật toán để tự động chia dữ liệu thành các nhóm thị trường khác nhau. Có thể bạn sẽ tìm ra rằng người mua nhà ở khu vực gần trường đại học thích mua nhà nhỏ với nhiều phòng ngủ, nhưng người mua nhà ở vùng ngoại ô thích nhà có 3 phòng ngủ hơn, diện tích lớn hơn. Biết được những loại khách hàng này sẽ giúp ích rất nhiều tới chiến lược kinh doanh.
Một điều thú vị nữa là bạn có thể làm là tự động xác định các ngôi nhà đặc biệt khác biệt (outlier). Bạn có thể tập trung những người bán hàng giỏi nhất vào những ngôi nhà thuộc dạng outlier này (biệt thự lớn, giá trị cao), vì mức hoa hồng sẽ cao hơn.
Supervised learning sẽ được tập trung giới thiệu ở những phần còn lại của bài viết này, nhưng không có nghĩa là unsupervised learning vô dụng hơn hoặc không thú vị bằng. Thực tế, unsupervised learning ngày càng quan trọng hơn bởi vì nó có thể được áp dụng mà không cần có nhãn (label) mà vẫn cho được kết quả đúng.
Note: có rất nhiều loại thuật toán machine learning khác. Nhưng supervised learning và unsupervised learning là hai nhóm cơ bản tốt nhất khi bắt đầu nghiên cứu vào machine learning.
Có đúng là việc ước lượng (estimate) được giá của một ngôi nhà là “learning” hay không?
Với con người, bộ não của chúng ta có thể tiếp cận mọi vấn đề và học cách giải quyết nó mà không cần chỉ dẫn chi tiết nào. Nếu bạn bán nhà trong một thời gian dài, theo bản năng bạn có thể cảm giác được đâu là giá chính xác của một căn nhà. Mục tiêu của ngành AI là lặp lại được điều đó với máy tính.
Nhưng hiện tại các thuật toán của machine learning của máy tính vẫn chưa đủ tốt, chúng chỉ giải quyết được những vấn đề rất cụ thể và giới hạn. Chúng ta có lẽ nên định nghĩa “learning” ở đây là “tìm ra được cách giải một bài toán cụ thể dựa vào vài ví dụ”.
Không may “tìm ra được cách giải một bài toán cụ thể dựa vào vài ví dụ” không phải là cái tên hay, thay vào đó mọi người gọi ngắn gọn là “Machine Learning”.
Let’s write that program!
Vậy, làm thế nào để có thể code được chương trình cho ví dụ trên? Bạn có thể suy nghĩ một chút trước khi đọc phần tiếp theo.
Nếu bạn không biết gì về machine learning, theo cách thông thường bạn có thể cố viết ra một số quy luật cơ bản để ước lượng giá nhà như sau:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# In my area, the average house costs $200 per sqft
price_per_sqft = 200
if neighborhood == "hipsterton":
# but some areas cost a bit more
price_per_sqft = 400
elif neighborhood == "skid row":
# and some areas cost less
price_per_sqft = 100
# start with a base price estimate based on how big the place is
price = price_per_sqft * sqft
# now adjust our estimate based on the number of bedrooms
if num_of_bedrooms == 0:
# Studio apartments are cheap
price = price — 20000
else:
# places with more bedrooms are usually
# more valuable
price = price + (num_of_bedrooms * 1000)
return priceCho dù bạn bỏ ra thêm hàng giờ nữa để code chương trình này, chương trình của bạn vẫn sẽ không bao giờ hoàn hảo và khó để bảo trì.
Tại sao bạn không để máy tính giúp bạn tự tìm ra kết quả?
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = <computer, please do some math for me>
return priceMột ý tưởng để giải quyết vấn đề này là bạn biết được price được tính bằng tổ hợp của number of bedrooms, square footage và neighborhood. Nếu bạn có thể chỉ ra mỗi thành phần tác động đến price cuối cùng như thế nào, vậy có lẽ sẽ tồn tại một tỉ lệ nào đó để kết hợp 3 chỉ số trên để có được price.
Với suy nghĩ trên, bạn có thể rút lại chương trình ban đầu thành như này:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * .841231951398213
# and a big pinch of that
price += sqft * 1231.1231231
# maybe a handful of this
price += neighborhood * 2.3242341421
# and finally, just a little extra salt for good measure
price += 201.23432095
return priceChúng ta có những con số đặc biệt sau: 0.841231951398213, 1231.1231231, 2.3242341421 và 201.23432095. Đây sẽ là các trọng số weights. Nếu bạn có thể tìm ra được weights hoàn hảo vừa khớp cho mọi căn nhà, chương trình của chúng ta có thể predict được giá nhà!
Một cách ngớ ngẩn để tìm ra weight tốt nhất mà mình có thể làm là:
Bước 1: Đặt tất cả weight là 1.0
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * 1.0
# and a big pinch of that
price += sqft * 1.0
# maybe a handful of this
price += neighborhood * 1.0
# and finally, just a little extra salt for good measure
price += 1.0
return priceBước 2: Với dữ liệu training data mọi căn nhà mà bạn biết giá, sử dụng chương trình trên để đoán giá và xem thử giá này cách xa với giá thực tế bao nhiêu:

Sử dụng function để predict giá nhà
Ví dụ với dòng đầu tiên, thực tế nó được bán với giá 178,000, chênh lệch $72,000.
Bây giờ bạn cộng tổng các bình phương giá chênh lệch của mỗi căn nhà trong tập dữ liệu. Giả sử như bạn có 500 căn nhà, và tổng bình phương chênh lệch từ hàm đoán giá của chúng ta so với thực tế là $86,123,373 - con số này thể hiện mức độ “lỗi” của chương trình của chúng ta.
Tiếp đến ta lấy tổng đó chia cho 500 để lấy trung bình độ chênh lệnh của mỗi ngôi nhà. Gọi nó là độ lỗi trung bình cost function.
Nếu bạn có được cost bằng 0 nếu thay đổi các weights, function của bạn sẽ hoàn hảo. Có nghĩa là trong mọi trường hợp, function sẽ đoán chính xác giá của mọi ngôi nhà được đưa vào theo dữ liệu.
Và đây cùng là nhiệm vụ của chúng ta: làm sao để có được cost thấp nhất có thể bằng cách thử các weights khác nhau.
Bước 3: Lặp lại bước 2 với mọi tổ hợp weights có thể có. Tìm ra tổ hợp nào giúp ta có được cost gần 0 nhất. Một khi bạn tìm ra được tập weights này, bài toán được giải quyết!
Thật đơn giản đúng không? Bạn lấy một vài dòng dữ liệu, thực hiện 3 bước đơn giản và bạn có được chương trình có thể đoán được giá của mọi căn nhà.
Nhưng khoan, hay xem lại. Có một vài điều sẽ khiến bạn ngạc nhiên:
- Phương pháp “ngớ ngẫn” trên có thể vượt lên đánh bại các chuyên gia.
- Function của bạn có được một cách ngớ ngẫn. Nó không biết “square feet” hay “bedrooms” là gì. Tất cả những gì nó biết là tìm ra con số để có được kết quả đúng.
- Bạn cũng sẽ không biết tại sao các weights đó lại giúp function trả về kết qủa đúng. Vì thế bạn cũng sẽ không thể hiểu để chứng minh rằng nó hoạt động chính xác.
- Tưởng tượng rằng thay vì bạn truyền giá trị cho các tham số “sqft” hay “num_of_bedrooms”, predict function có thể nhận một mảng các con số. Ví dụ như mỗi con số là độ sáng của pixel ảnh được chụp từ camera gắn ở trước xe hơi của bạn. Chương trình thay vì dự đoán giá nhà, bạn có thể sẽ có chương trình “degrees_to_turn_steering_wheel” (điều chỉnh vô lăng xe hơi). Bạn mới vừa viết ra chương trình để xe hơi tự lái!!
Thật điên rồi đúng không :v
Thử “mọi tổ hợp weights có thể có” ở bước 3
Dĩ nhiên bạn hoàn toàn có thể thử mọi tổ hợp số, hoặc là bạn sẽ có kết quả tốt, hoặc là bạn sẽ thử suốt đời mới xong.
Để tránh điều này, toán học có nhiều cách làm “thông minh” để nhanh chóng tìm ra các weights này mà không cần phải thử quá nhiều lần. Đây là một cách:
Đầu tiên, viết một biểu thức đơn giản để biểu diễn cost ở bước 2 ở trên:
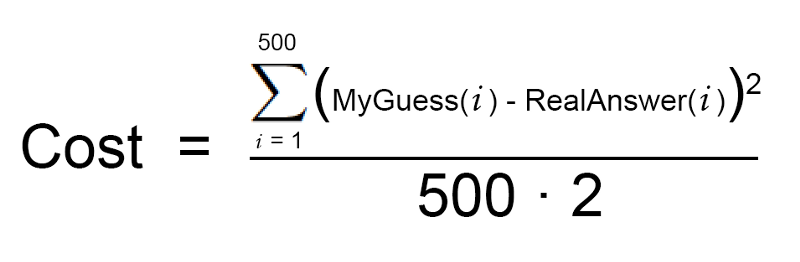
cost function.
Bây giờ chúng ta viết lại dưới dạng một biểu thức với ký hiệu toán machine learning (không hiểu không sao, có thể bỏ qua):
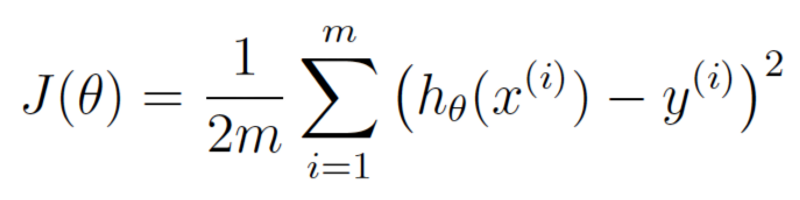
θ biểu diễn cho weights, J(θ) có nghĩa là cost của weight hiện có.
Công thức trên biểu diễn độ sai của function ước lượng price của chúng ta với tập weights θ.
Nếu chúng ta vẽ hết tất cả giá trị của biểu thức J(θ) với các weights có thể có ứng với number_of_bedrooms và sqft, biểu đồ sẽ có thể có dạng như sau:

Trục đứng thể hiện cost. Đồ thị của cost function sẽ có dạng hình cái bát.
Trên hình trên, điểm thấp nhất màu xanh ứng với nơi có cost thấp nhất - vì thế chương trình sẽ có độ lỗi thấp nhất. Điểm càng cao sẽ có độ lệch/lỗi càng cao. Vì thế nếu chúng ta có thể tìm được weights đưa chúng ta đến điểm thấp nhất trên đồ thị, chúng ta sẽ tìm ra được câu trả lời!

Vì thế, chúng ta cần điều chỉnh weights, giống như việc “đi xuống thung lũng” trong đồ thị để tìm được điểm thấp nhất. Nếu như chúng ta điều chỉnh từng chút một và luôn đi xuống, ta sẽ tìm được điểm cực tiểu mà không cần phải thử quá nhiều weights.
Nếu bạn còn nhớ trong môn Đại số, nếu bạn đạo hàm một hàm số, bạn sẽ biết được hàm số đồng biến (hướng lên) hay nghịch biến (hướng xuống) tại mọi điểm tiếp tuyến, có nghĩa là bạn sẽ biết được độ dốc của mọi điểm trên đồ thị.
Vì vậy, nếu chúng ta đạo hàm cost function, tính giá trị tại điểm đạo hàm đó, trừ giá trị này với từng weight, từng bước như vậy sẽ giúp ta di chuyển dần đến điểm thấp nhất của đồ thị.
Ở trên là một cách tốt nhất để tìm weights tối ưu, người ta gọi nó là batch gradient descent. Nếu bạn quan tâm muốn đi sâu hơn, có thể đọc tiếp bài viết này: http://hbfs.wordpress.com/2012/04/24/introduction-to-gradient-descent/.
Những thứ có thể bị skip qua nhanh
Thuật toán 3 bước được giới thiệu ở trên được gọi là multivariate linear regression. Bạn có thể ước lượng được biểu thức để có thể fit tất cả dòng dữ liệu đang có. Sau đó bạn dùng biểu thức để đoán giá của những căn nhà khác, dựa vào giá của những căn có trong dữ liệu qúa khứ. Đây là một ý tưởng rất tuyệt, và có thể triển khai được trong thực tế.
Nhưng ý tưởng tôi đã trình bày chỉ đúng với trường hợp đơn giản, sẽ có vài ngoại lệ. Vì giá nhà đất không phải lúc nào cũng theo một đường, một quy luật cố định.
May mắn là có nhiều thuật toán khác có thể giải quyết vấn đề này, xử lý được dữ liệu phi tuyến tính như neural networks hoặc SVMs với kernels. Hoặc cũng có thể sử dụng linear regression khéo léo hơn, cho phép tạo ra đường fit nhất với dữ liệu.
Tương tự, tôi cũng bỏ qua trường hợp overfitting. Đây là trường hợp các weights khớp và đoán đúng mọi căn nhà trong dữ liệu training, nhưng không đúng với những căn khác ngoài tập dữ liệu.
Có nhiều cách để giải quyết vấn đề này như regularization và sử dụng cross-validation trên data set. Học cách để giải quyết những vấn đề trên cũng là một mục tiêu để ứng dụng thành công machine learning.
Machine Learning toàn năng?
Một khi nhìn thấy cách mà machine learning giải quyết những vấn đề rất phức tạp một cách dễ dàng (như nhận diện khuôn mặt, chữ viết), người ta thường sẽ nghĩ rằng machine learning sẽ giải quyết được mọi vấn đề nếu như có đủ data.
Nhưng, hãy nhớ rằng machine learning chỉ có thể hoạt động nếu vấn đề có-thể-giải-quyết được với dữ liệu bạn đang có.
Ví dụ, bạn xây dựng mô hình dự đoán giá nhà dựa vào các loại chậu cây trồng trước nhà, nó sẽ không bao giờ hoạt động. Giá nhà và chậu cây chẳng liên quan gì nhau cả.

Vì vậy hãy nhớ nếu một chuyên gia không thể sử dụng dữ liệu của giải quyết vấn đề, thì máy tính cũng vậy.
Làm thế nào để tìm hiểu nhiều hơn về Machine Learning
Tác giả đã tạo một khóa học từng bước một về chuỗi bài viết này, kể cả viết code.
Nếu bạn muốn đi sâu hơn, hãy thử khóa học Machine Learning trên Coursera của Andrew Ng.
Ngoài ra, bạn cũng có thể thử đủ loại thuật toán trong thư viện Scikit-learn của Python.