Data Engineer
← Back to All Tags
Phân lớp văn bản
Trong Machine Learning và NLP, phân lớp văn bản là một bài toán xử lí văn bản cổ điển, gán các nhãn phân loại lên một văn bản mới dựa trên mức độ tương tự của văn bản đó so với các văn bản đã được gán nhãn trong tập huấn luyện.
natural - NLTK cho Javascript
NaturalJS được ví như nltk cho Node. natural có nhiều chức năng xử lý ngôn ngữ tự nhiên như: Tokenizing, stemming, classification, phonetics, tf-idf, WordNet, string similarity, ...

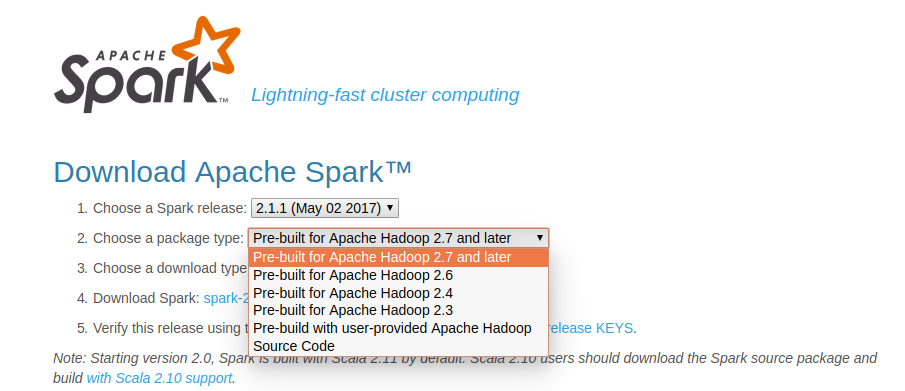
Cài Apache Spark standalone bản pre-built
Mình nhận được nhiều phản hồi từ bài viết BigData - Cài đặt Apache Spark trên Ubuntu 14.04 rằng sao cài khó và phức tạp thế. Thực ra bài viết đó mình hướng dẫn cách build và install từ source.
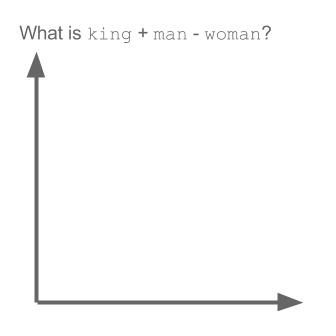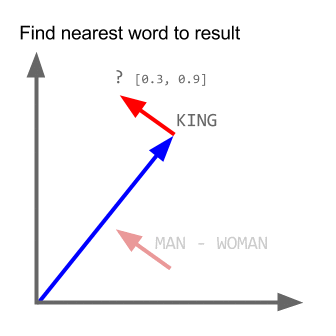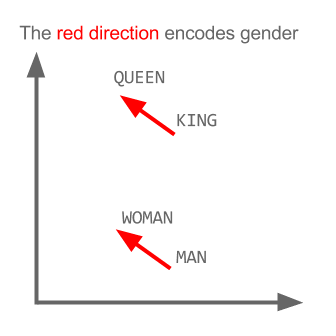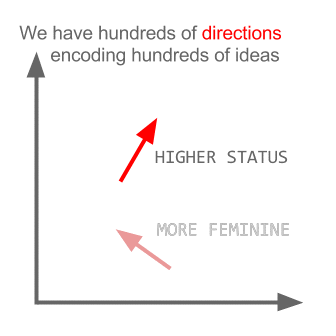
NLP - Truyện Kiều Word2vec
Trong các dự án gần đây mình làm nhiều về Word2vec, khá có vẻ là useful trong việc biểu diễn word lên không gian vector (word embedding). Nói thêm về Word2vec, trong các dự án nghiên cứu W2V của Google còn khám phá được ra tính ngữ nghĩa, cú pháp của các từ ở một số mức độ nào đó
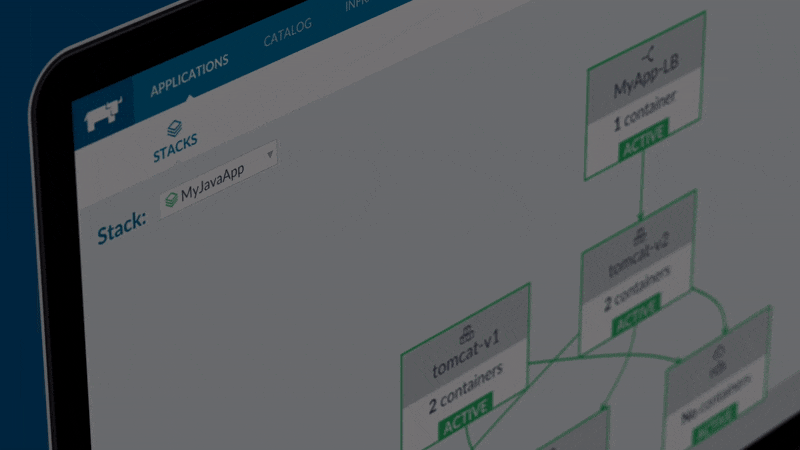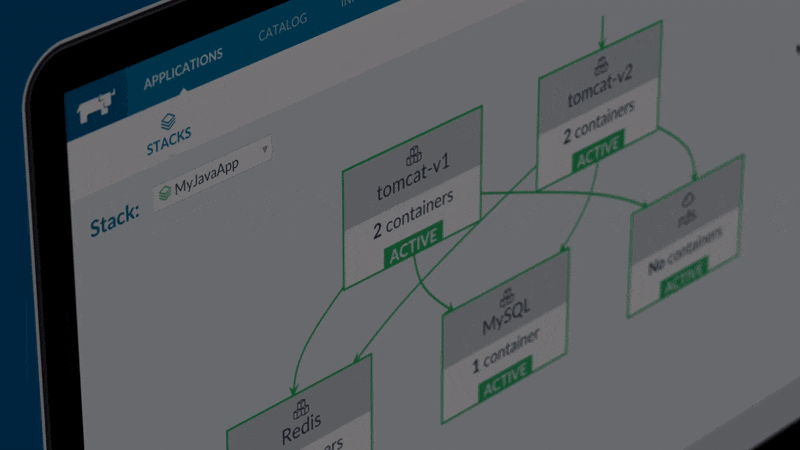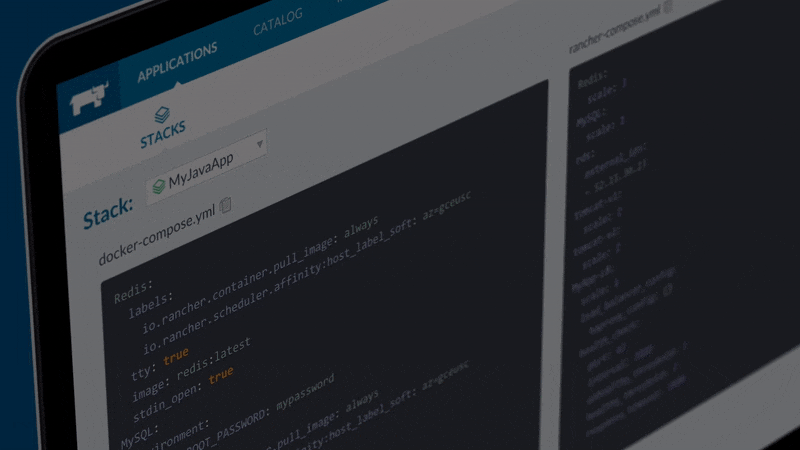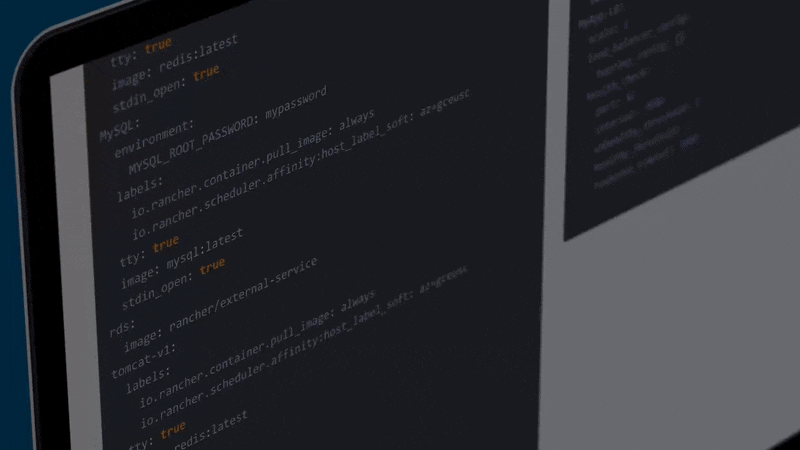
Rancher - Quản lý Docker Container bằng UI
Rancher giúp quản lý Docker bằng UI Web một cách tiện dụng, mọi thao tác đều trên UI. Rancher còn tích hợp Shell trên Docker, App catalog, ...
vnTokenizer trên PySpark
Trong blog này mình sẽ custom lại vn.vitk để có thể chạy như một thư viện lập trình, sử dụng ngôn ngữ python (trên PySpark và Jupyter Notebook).
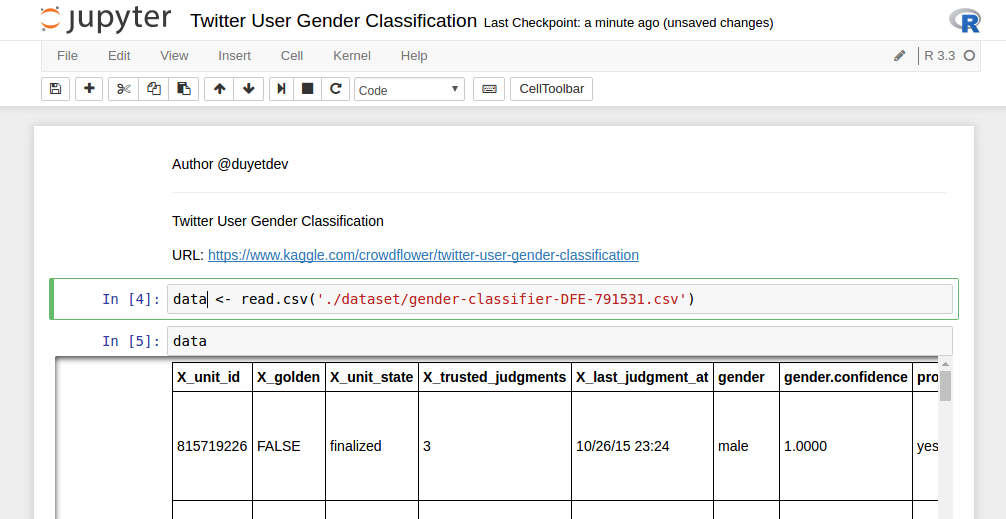
R trên Jupiter Notebook (Ubuntu 14.04 / 14.10 / 16.04)
Jupyter Notebook là công cụ khá mạnh của lập trình viên Python và Data Science. Nếu dùng R, Jupyter cũng cho phép ta tích hợp R kernel vào Notebook một cách dễ dàng.