NLP
← Back to All Tags
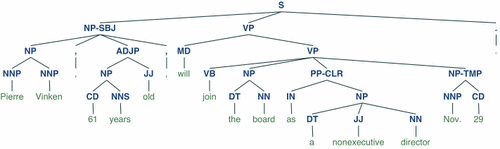
Phân lớp văn bản
Trong Machine Learning và NLP, phân lớp văn bản là một bài toán xử lí văn bản cổ điển, gán các nhãn phân loại lên một văn bản mới dựa trên mức độ tương tự của văn bản đó so với các văn bản đã được gán nhãn trong tập huấn luyện.
natural - NLTK cho Javascript
NaturalJS được ví như nltk cho Node. natural có nhiều chức năng xử lý ngôn ngữ tự nhiên như: Tokenizing, stemming, classification, phonetics, tf-idf, WordNet, string similarity, ...

vnTokenizer trên PySpark
Trong blog này mình sẽ custom lại vn.vitk để có thể chạy như một thư viện lập trình, sử dụng ngôn ngữ python (trên PySpark và Jupyter Notebook).
Japanese stopwords package for npm, bower and plaintext
Japanese stopwords, available for npm, bower, plaintext. 日本のストップワード

