Python
← Back to All Tags
NLP - Truyện Kiều Word2vec
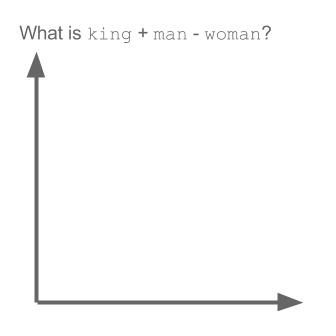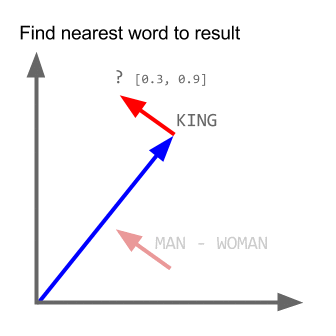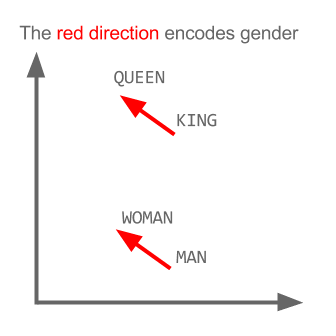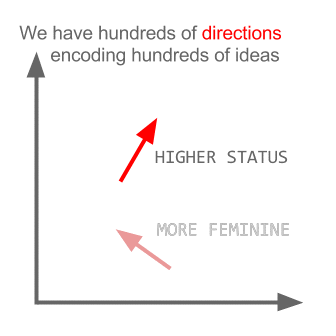
Trong các dự án gần đây mình làm nhiều về Word2vec, khá có vẻ là useful trong việc biểu diễn word lên không gian vector (word embedding). Nói thêm về Word2vec, trong các dự án nghiên cứu W2V của Google còn khám phá được ra tính ngữ nghĩa, cú pháp của các từ ở một số mức độ nào đó
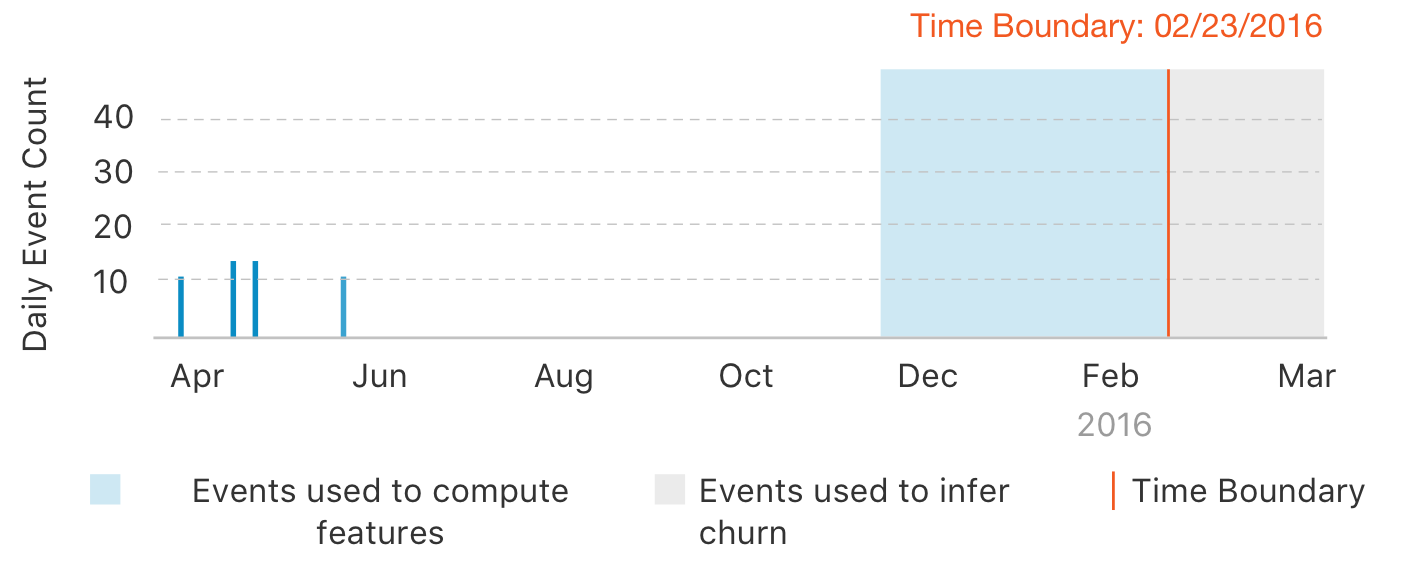
Python - Churn prediction with Graphlab
Churn prediction is the task of identifying whether users are likely to stop using a service, product, or website. With Graphlab toolkit, you can start with raw (or processed) usage metrics and accurately forecast the probability that a given customer will churn.
vnTokenizer trên PySpark
Trong blog này mình sẽ custom lại vn.vitk để có thể chạy như một thư viện lập trình, sử dụng ngôn ngữ python (trên PySpark và Jupyter Notebook).
R trên Jupiter Notebook (Ubuntu 14.04 / 14.10 / 16.04)
Jupyter Notebook là công cụ khá mạnh của lập trình viên Python và Data Science. Nếu dùng R, Jupyter cũng cho phép ta tích hợp R kernel vào Notebook một cách dễ dàng.
Openstack - App Catalog và Docker trên Devstack
DevStack là giúp triển khai mô hình Openstack cho Developers, có thể chạy trên Single-Machine

Spark: Convert Text (CSV) to Parquet để tối ưu hóa Spark SQL và HDFS
Lưu trữ dữ liệu dưới dạng Columnar như Apache Parquet góp phần tăng hiệu năng truy xuất trên Spark lên rất nhiều lần. Bởi vì nó có thể tính toán và chỉ lấy ra 1 phần dữ liệu cần thiết (như 1 vài cột trên CSV), mà không cần phải đụng tới các phần khác của data row. Ngoài ra Parquet còn hỗ trợ flexible compression do đó tiết kiệm được rất nhiều không gian HDFS.
![]()
Chạy Apache Spark với Jupyter Notebook
IPython Notebook là một công cụ tiện lợi cho Python. Ta có thể Debug chương trình PySpark Line-by-line trên IPython Notebook một cách dễ dàng, tiết kiệm được nhiều thời gian.

PySpark - Thiếu thư viện Python trên Worker
Apache Spark chạy trên Cluster, với Java thì đơn giản. Với Python thì package python phải được cài trên từng Node của Worker. Nếu không bạn sẽ gặp phải lỗi thiếu thư viện.
