Machine Learning
← Back to All Tags
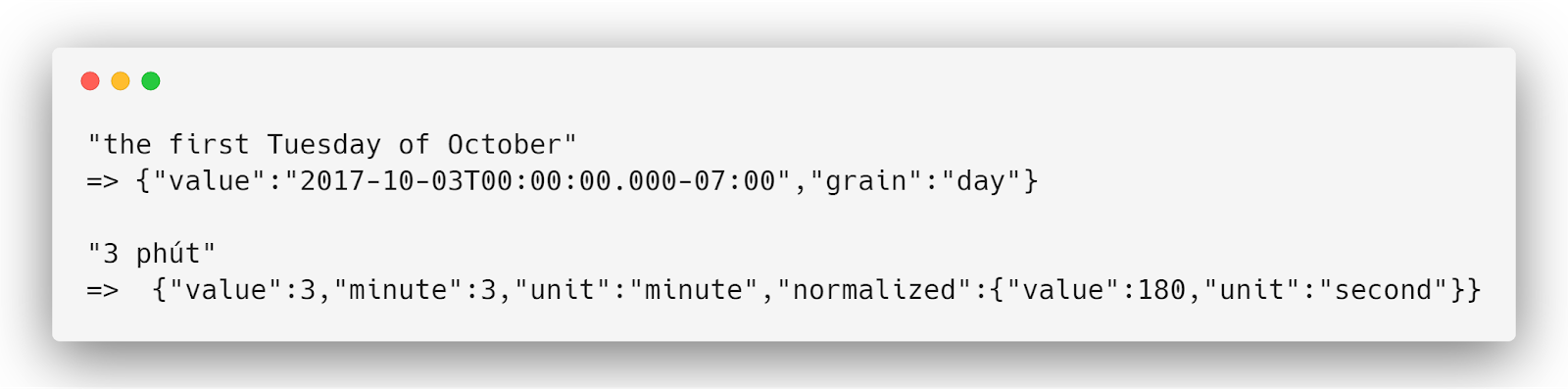
Duckling - phân tích văn bản sang dữ liệu có cấu trúc
Duckling là một thư viện của Haskell, phát triển bởi Facebook, rất hay để phân tích (parses) dữ liệu text sang dạng có cấu trúc (structured data). Công cụ này rất hữu ích trong các ứng dụng phân tích văn bản trong NLP và nhất là lĩnh vực chatbot.
Doc2vec trong Sentiment Analysis
Doc2vec, ngoài từ (word), ta còn có thể biểu diễn các câu (sentences) thậm chí 1 đoạn văn bản (document). Khi đó, bạn có thể dễ dàng vector hóa cả một đoạn văn bản thành một vector có số chiều cố định và nhỏ, từ đó có thể chạy bất cứ thuật toán classification cơ bản nào trên các vector đó.

Python - Nhận dạng xe hơi với OpenCV
Trong bài này, mình sẽ hướng dẫn sử dụng OpenCV để nhận diện xe hơi trong ảnh (video frame) với đặc trưng HAAR, sử dụng file mô hình đã được trained.

Machine Learning is Fun! (Vietnamese version)
Chuỗi bài viết "Machine Learning is Fun!" này mình lược dịch từ bài viết gốc của tác giả ageitgey. Mình tin chắc có rất nhiều bạn đã và đang quan tâm đến Machine Learning hiện nay. "Machine Learning is Fun!" chắc chắn sẽ mang cho bạn đến cho bạn cái nhìn từ cơ bản đến chuyên sâu nhất về thế giới Machine Learning.
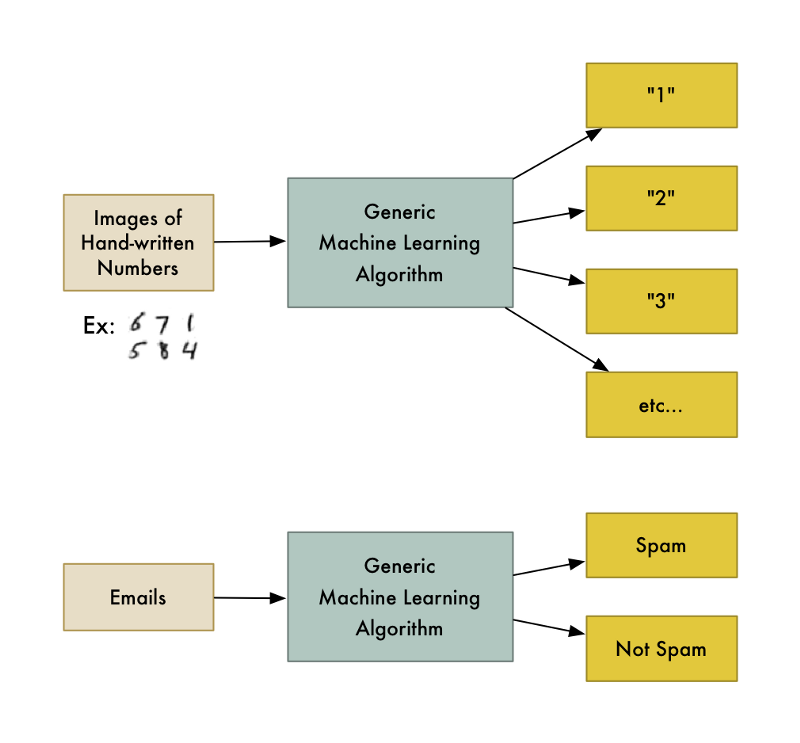
Phân lớp văn bản
Trong Machine Learning và NLP, phân lớp văn bản là một bài toán xử lí văn bản cổ điển, gán các nhãn phân loại lên một văn bản mới dựa trên mức độ tương tự của văn bản đó so với các văn bản đã được gán nhãn trong tập huấn luyện.
natural - NLTK cho Javascript
NaturalJS được ví như nltk cho Node. natural có nhiều chức năng xử lý ngôn ngữ tự nhiên như: Tokenizing, stemming, classification, phonetics, tf-idf, WordNet, string similarity, ...

NLP - Truyện Kiều Word2vec
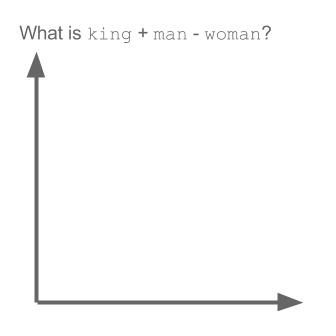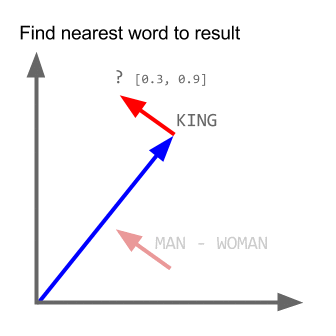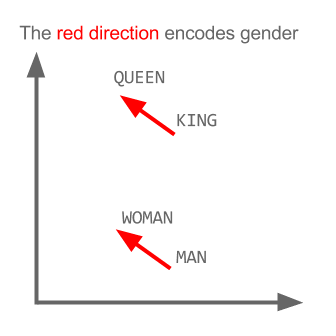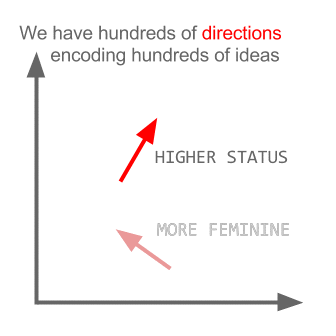
Trong các dự án gần đây mình làm nhiều về Word2vec, khá có vẻ là useful trong việc biểu diễn word lên không gian vector (word embedding). Nói thêm về Word2vec, trong các dự án nghiên cứu W2V của Google còn khám phá được ra tính ngữ nghĩa, cú pháp của các từ ở một số mức độ nào đó
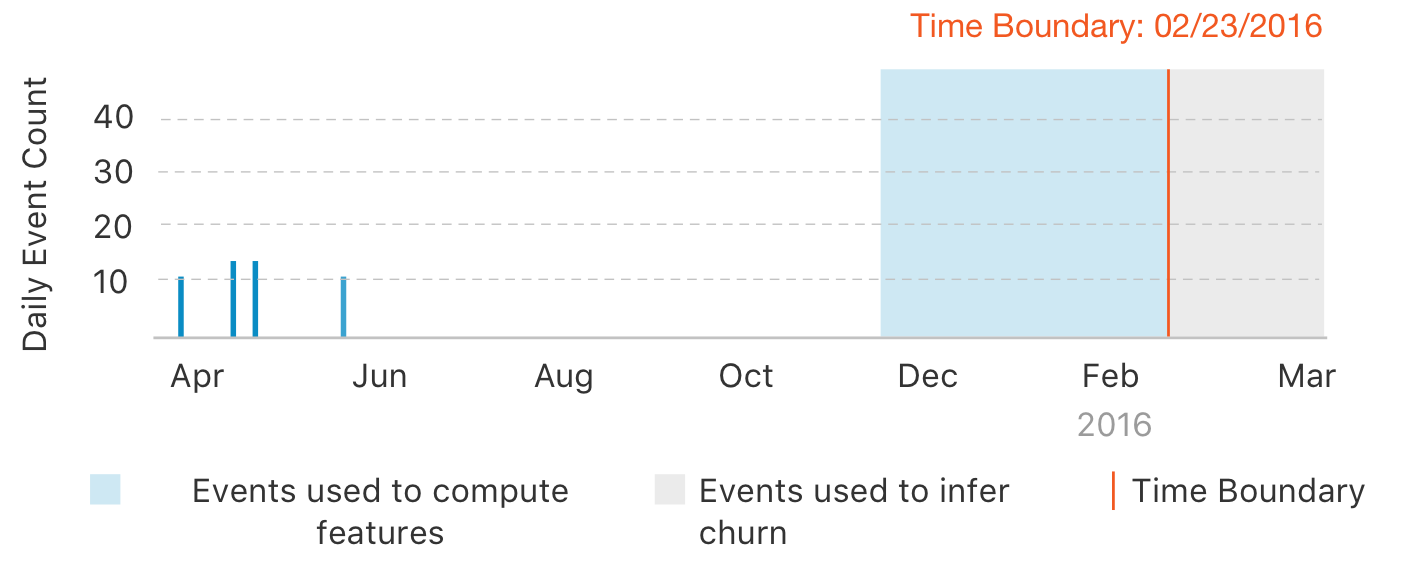
Python - Churn prediction with Graphlab
Churn prediction is the task of identifying whether users are likely to stop using a service, product, or website. With Graphlab toolkit, you can start with raw (or processed) usage metrics and accurately forecast the probability that a given customer will churn.