Spark
← Back to All Tags
Chạy Apache Spark với Jupyter Notebook
IPython Notebook là một công cụ tiện lợi cho Python. Ta có thể Debug chương trình PySpark Line-by-line trên IPython Notebook một cách dễ dàng, tiết kiệm được nhiều thời gian.

PySpark - Thiếu thư viện Python trên Worker
Apache Spark chạy trên Cluster, với Java thì đơn giản. Với Python thì package python phải được cài trên từng Node của Worker. Nếu không bạn sẽ gặp phải lỗi thiếu thư viện.
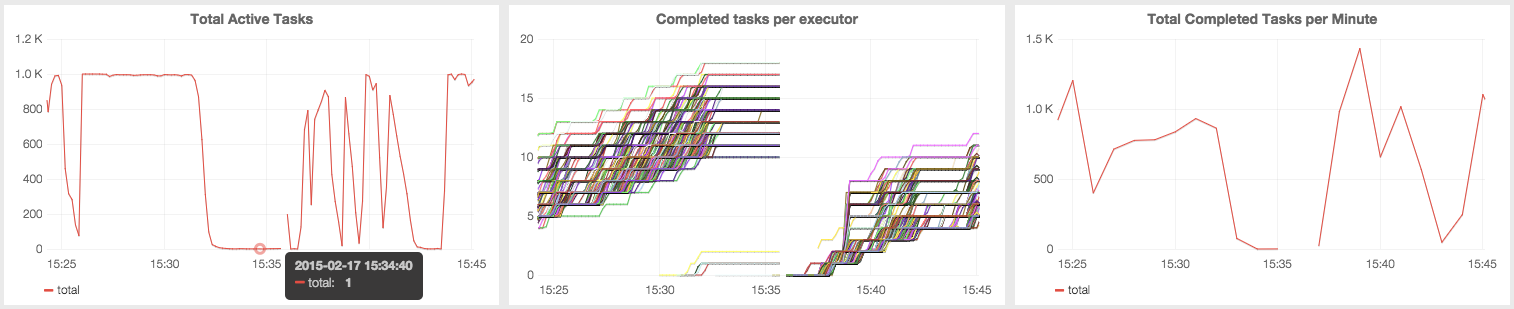
Bigdata - Getting Started with Spark (in Python)
Hadoop is the standard tool for distributed computing across really large data sets and is the reason why you see "Big Data" on advertisements as you walk through the airport. It has become an operating system for Big Data, providing a rich ecosystem of tools and techniques that allow you to use a large cluster of relatively cheap commodity hardware to do computing at supercomputer scale. Two ideas from Google in 2003 and 2004 made Hadoop possible: a framework for distributed storage (The Google File System), which is implemented as HDFS in Hadoop, and a framework for distributed computing (MapReduce).
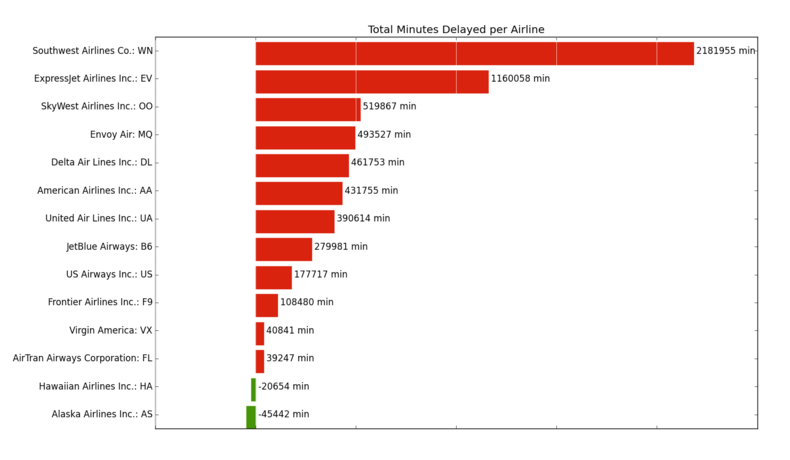
BigData - Cài đặt Apache Spark trên Ubuntu 14.04
Trong lúc tìm hiểu vài thứ về BigData cho một số dự án, mình quyết định chọn Apache Spark thay cho Hadoop. Theo như giới thiệu từ trang chủ của Apache Spark, thì tốc độ của nó cao hơn 100x so với Hadoop MapReduce khi chạy trên bộ nhớ, và nhanh hơn 10x lần khi chạy trên đĩa, tương thích hầu hết các CSDL phân tán (HDFS, HBase, Cassandra, ...). Ta có thể sử dụng Java, Scala hoặc Python để triển khai các thuật toán trên Spark.

