Spark
← Back to All Tags
Spark on Kubernetes tại Fossil 🤔
Apache Spark được chọn làm công nghệ cho Batch layer bởi khả năng xử lý một lượng lớn data cùng một lúc. Ở thiết kế ban đầu, team data chọn sử dụng Apache Spark trên AWS EMR do có sẵn và triển khai nhanh chóng. Dần dần, AWS EMR bộc lộ một số điểm hạn chế trên môi trường Production. Trong bài viết này, mình sẽ nói về tại sao và làm thế nào team Data chuyển từ Spark trên AWS EMR sang Kubernetes.

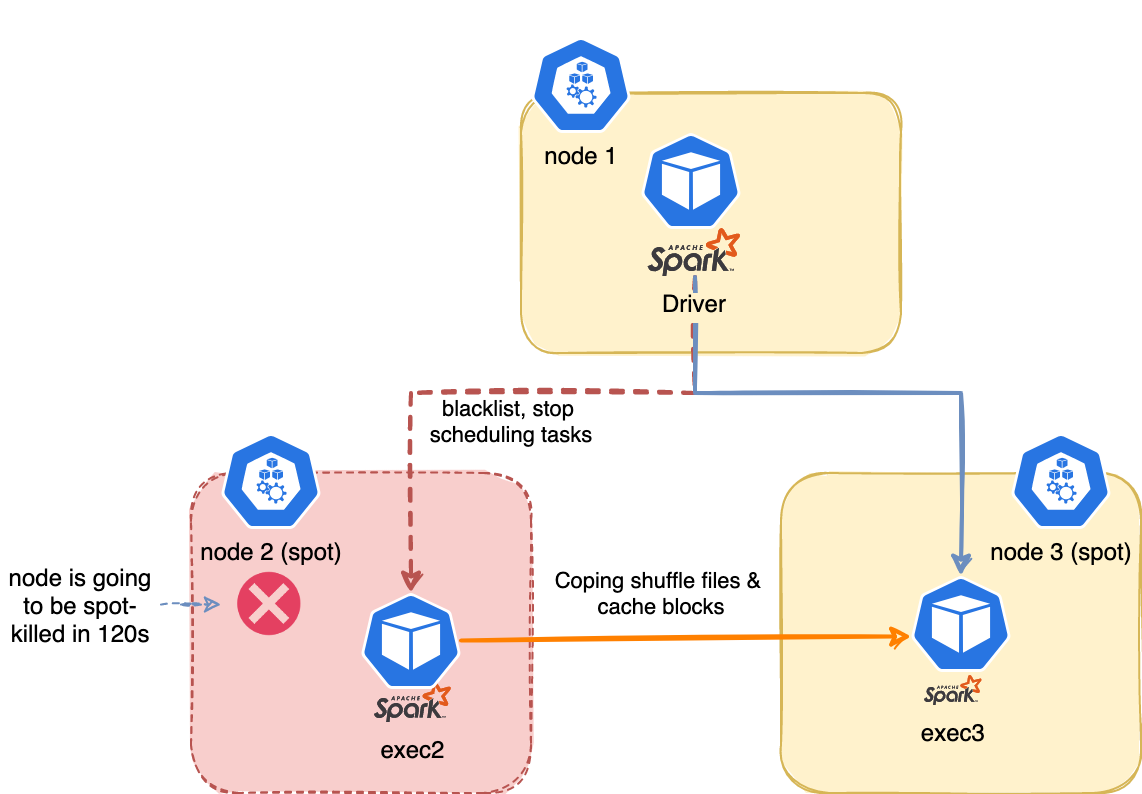
Spark on Kubernetes - better handling for node shutdown
Spark 3.1 on the Kubernetes project is now officially declared as production-ready and Generally Available. Spot instances in Kubernetes can cut your bill by up to 70-80% if you are willing to trade in reliability. The new feature - SPIP: Add better handling for node shutdown (SPARK-20624) was implemented to deal with the problem of losing an executor when working with spot nodes - the need to recompute the shuffle or cached data.
Spark on Kubernetes Performance Tuning
Spark Performance tuning is a process to improve the performance of the Spark, on this post, I will focus on Spark that runing of Kubernetes.

Tại sao nên triển khai Apache Spark trên Kubernetes
Spark đã quá nổi tiếng trong thế giới Data Engineering và Bigdata. Kubernetes cũng ngày càng phổ biến tương tự, là một hệ thống quản lý deployment và scaling application. Bài viết này bàn đến một số lợi ích khi triển khai ứng dụng Apache Spark trên hệ thống Kubernetes.

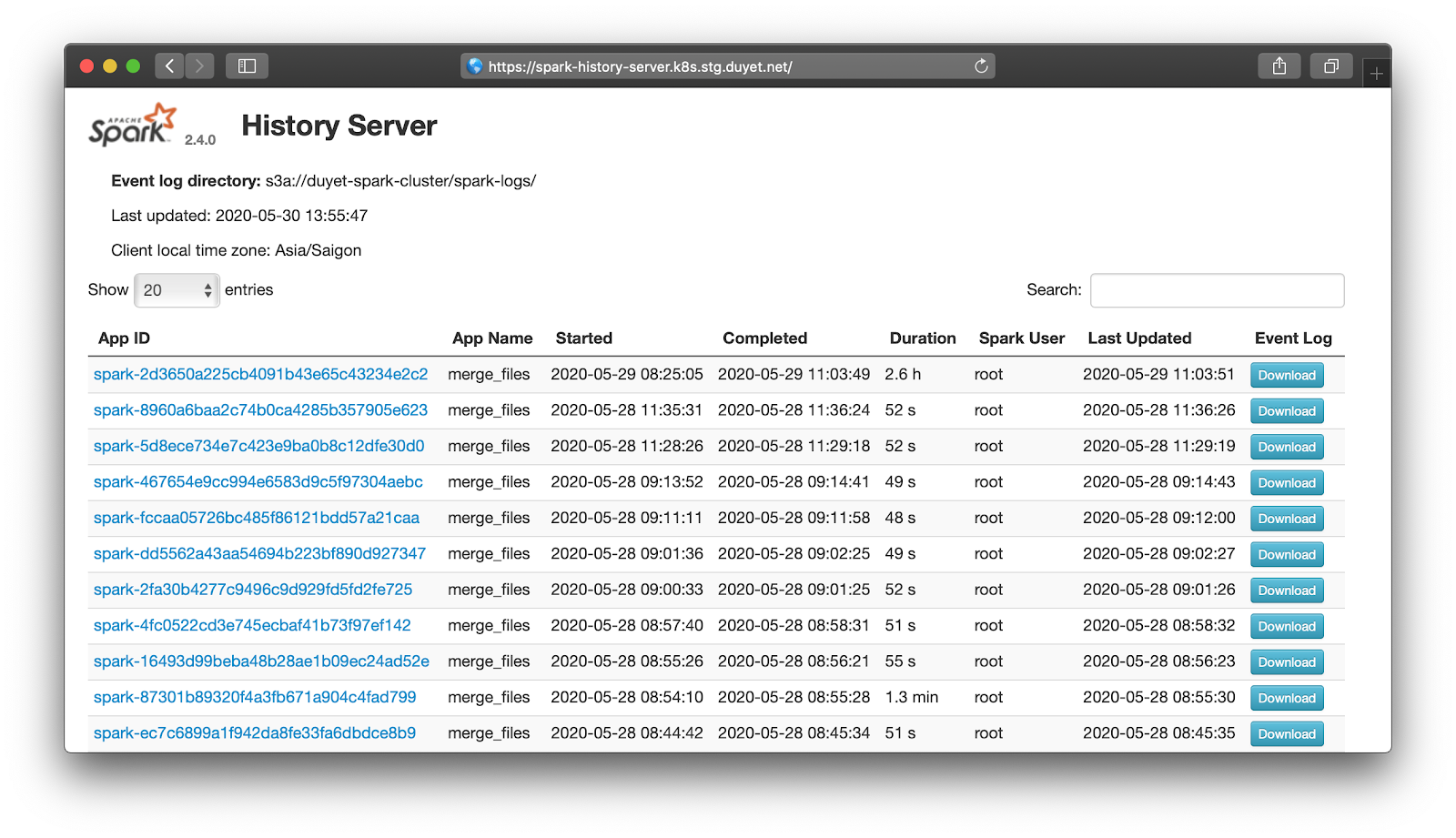
Spark History Server on Kubernetes
The problem with running Spark on Kubernetes is the logs go away once the job completes. Spark has tool called the Spark History Server that provides a UI for your past Spark jobs. In this post, I will show you how to use Spark History Server on Kubernetes.
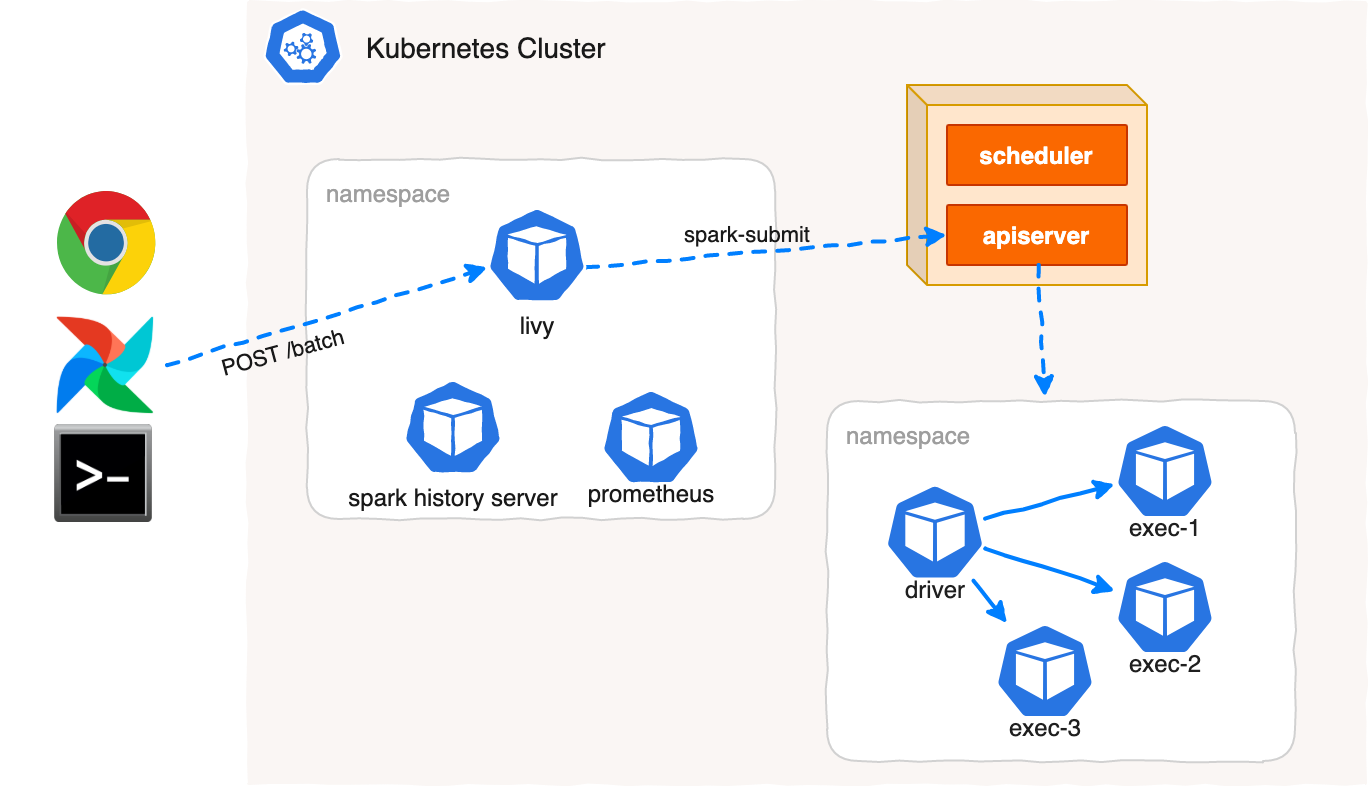
3 ways to run Spark on Kubernetes
Spark can run on clusters managed by Kubernetes. This feature makes use of native Kubernetes scheduler that has been added to Spark.
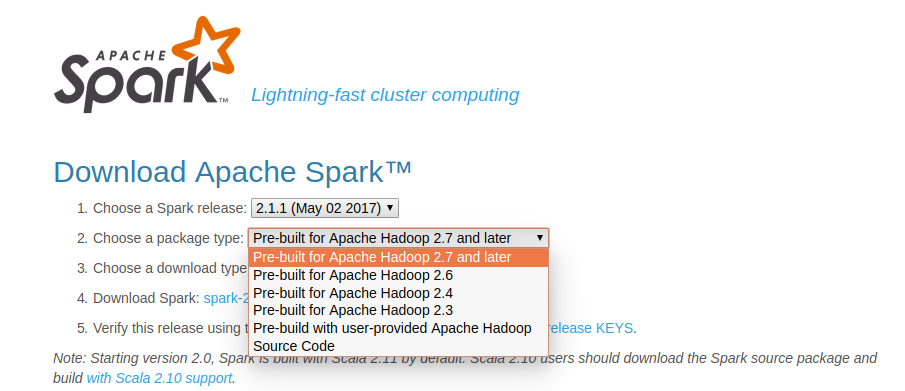
Cài Apache Spark standalone bản pre-built
Mình nhận được nhiều phản hồi từ bài viết BigData - Cài đặt Apache Spark trên Ubuntu 14.04 rằng sao cài khó và phức tạp thế. Thực ra bài viết đó mình hướng dẫn c�ách build và install từ source.
vnTokenizer trên PySpark
Trong blog này mình sẽ custom lại vn.vitk để có thể chạy như một thư viện lập trình, sử dụng ngôn ngữ python (trên PySpark và Jupyter Notebook).
